全方位斜率(下):掌握跨時間跨市場的趨勢洞察
[免責聲明] 本文僅供教育和資訊目的,不構成投資建議。您需對自身的投資決策負完全責任。
浩外(Fxcns.com)對因使用本網站提供的資訊而可能造成的任何財務損失概不負責。
④ 開發多維度斜率指標
隨著我們對時間框架和市場關聯性的理解加深,是時候將這些知識整合成一個更全面的分析工具了。在量化交易實踐中,我發現將多個維度的斜率資訊有機結合,能夠提供更可靠的市場洞察。
4.1 綜合短期、中期和長期斜率的複合指標
首先,讓我們發展一個整合多個時間維度的複合指標:
class MultiTimeframeSlopeIndicator:
def __init__(self, timeframes={'short': '1h', 'medium': '4h', 'long': '1d'},
windows={'short': 10, 'medium': 20, 'long': 30}):
self.timeframes = timeframes
self.windows = windows
def _calculate_adaptive_slope(self, data, window):
"""
計算自適應斜率
參數:
data: pd.Series, 價格數據
window: int, 計算視窗大小
"""
if len(data) < window:
print(f"警告: 資料長度 {len(data)} 小於視窗大小 {window}")
return pd.Series(np.nan, index=data.index)
# 確保資料是連續的,沒有缺失值
data = data.ffill().bfill()
# 計算波動率,使用簡單標準差
volatility = data.rolling(window=window, min_periods=1).std()
slopes = pd.Series(np.nan, index=data.index)
# 使用向量化操作計算斜率
for i in range(window, len(data) + 1):
y = data.iloc[i-window:i].values
x = np.arange(window)
if len(y) == window:
slope, _ = np.polyfit(x, y, 1)
vol = volatility.iloc[i-1]
# 標準化斜率
slopes.iloc[i-1] = slope / vol if vol != 0 else slope
return slopes
def calculate_composite_slope(self, price_data):
"""
計算複合斜率指標
"""
# 初始化結果DataFrame
composite_slopes = pd.DataFrame(index=price_data.index)
price_data = price_data.ffill().bfill() # 確保價格資料連續
# 為每個時間框架計算斜率
for tf_name, tf in self.timeframes.items():
# 重採樣數據
resampled = price_data.resample(tf).last()
resampled = resampled.ffill().bfill() # 確保重採樣資料連續
window = self.windows[tf_name]
if len(resampled) > window:
# 計算斜率
slopes = self._calculate_adaptive_slope(resampled, window)
# 對齊到原始時間框架
aligned_slopes = slopes.reindex(price_data.index).ffill(limit=int(pd.Timedelta(tf) / pd.Timedelta('1H')))
composite_slopes[tf_name] = aligned_slopes
# 刪除全部為NaN的行
composite_slopes = composite_slopes.dropna(how='all')
# 如果沒有有效數據,返回NaN序列
if composite_slopes.empty:
return pd.Series(np.nan, index=price_data.index)
# 計算動態權重
weights = self._calculate_dynamic_weights(composite_slopes)
composite = self._weighted_composite(composite_slopes, weights)
return composite.reindex(price_data.index)
def _calculate_dynamic_weights(self, slopes_data):
"""
基於趨勢一致性動態調整權重
參數:
slopes_data: DataFrame, 包含不同時間框架的斜率數據
"""
try:
# 使用新的方法處理NaN值
slopes_clean = slopes_data.ffill().bfill()
# 計算相關性矩陣
correlations = slopes_clean.corr()
# 計算每個時間框架的平均相關性
mean_corr = correlations.mean()
# 確保權重為正且和為1
weights = np.abs(mean_corr)
weights_sum = weights.sum()
if weights_sum > 0:
weights = weights / weights_sum
else:
# 如果所有權重都是0,使用均等權重
weights = pd.Series(1.0/len(slopes_data.columns), index=slopes_data.columns)
print("\n計算的權重:")
for tf, weight in weights.items():
print(f"{tf}: {weight:.3f}")
return weights
except Exception as e:
print(f"計算動態權重時發生錯誤: {e}")
# 回傳均等權重
return pd.Series(1.0/len(slopes_data.columns), index=slopes_data.columns)
def _weighted_composite(self, slopes_data, weights):
"""
計算加權綜合指標
參數:
slopes_data: DataFrame, 包含不同時間框架的斜率數據
weights: Series, 各時間框架的權重
"""
try:
# 使用新的方法處理NaN值
slopes_clean = slopes_data.ffill().bfill()
# 計算加權和
weighted_sum = pd.Series(0, index=slopes_clean.index)
for column in slopes_clean.columns:
weighted_sum += slopes_clean[column] * weights[column]
return weighted_sum
except Exception as e:
print(f"計算加權綜合指標時發生錯誤: {e}")
return pd.Series(np.nan, index=slopes_data.index)
def visualize_results(price_data, composite_slopes, indicator, year=2024, month=9):
"""
視覺化分析結果,先計算所有數據,然後只顯示指定月份
"""
# 先计算所有时间的斜率
slopes_data = pd.DataFrame(index=price_data.index)
# 先計算所有時間的斜率
for tf_name, tf in indicator.timeframes.items():
resampled = price_data.resample(tf).last()
resampled = resampled.ffill().bfill()
window = indicator.windows[tf_name]
if len(resampled) > window:
slopes = indicator._calculate_adaptive_slope(resampled, window)
aligned_slopes = slopes.reindex(price_data.index).ffill()
slopes_data[tf_name] = aligned_slopes
# 在計算所有資料後,選擇指定月份的資料進行繪圖
mask = (price_data.index.year == year) & (price_data.index.month == month)
selected_price = price_data[mask]
selected_slopes = slopes_data[mask]
selected_composite = composite_slopes[mask] if isinstance(composite_slopes, pd.Series) else None
# 建立圖表
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12), sharex=True)
# 建立數字索引
data_points = list(range(len(selected_price)))
# 繪製價格數據
ax1.plot(data_points, selected_price.values, label='Price', color='pink')
ax1.set_title(f'Price Data ({year}-{month:02d})')
ax1.grid(True)
ax1.legend()
# 繪製各時間框架的斜率
colors = {'short': 'red', 'medium': 'blue', 'long': 'green'}
for tf_name in slopes_data.columns:
ax2.plot(data_points, selected_slopes[tf_name].values,
label=f'{tf_name} Slope',
color=colors[tf_name],
linewidth=1)
ax2.set_title(f'Slopes by Timeframe ({year}-{month:02d})')
ax2.grid(True)
ax2.legend()
# 繪製複合斜率
if selected_composite is not None:
ax3.plot(data_points, selected_composite.values,
label='Composite Slope', color='red', linewidth=1)
ax3.set_title(f'Composite Slope ({year}-{month:02d})')
ax3.grid(True)
ax3.legend()
# 設定x軸標籤為日期
num_ticks = min(20, len(data_points)) # 可調整顯示的刻度數量
tick_indices = np.linspace(0, len(data_points)-1, num_ticks, dtype=int)
tick_dates = selected_price.index[tick_indices].strftime('%Y-%m-%d')
ax3.set_xticks(tick_indices)
ax3.set_xticklabels(tick_dates, rotation=45)
# 調整佈局
plt.tight_layout()
plt.show()
# 列印統計訊息
print(f"\n{year}年{month}月斜率統計資訊:")
print(selected_slopes.describe())
print("\n各時間框架的NaN數量:")
print(selected_slopes.isna().sum())
# 運行測試
if __name__ == "__main__":
visualize_results(price_data, composite_slopes, indicator, year=2024, month=9)
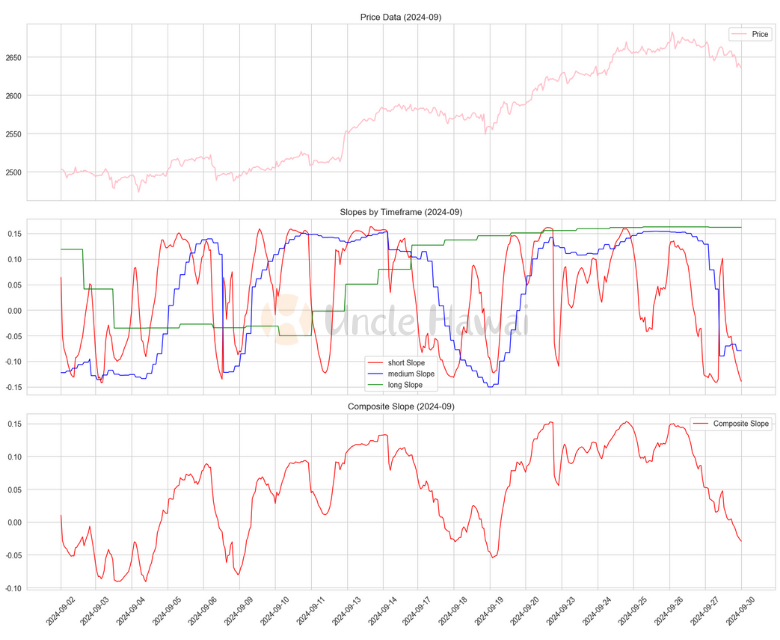
這個複合指標的創新之處在於:
- 自適應:根據市場波動性動態調整計算參數
- 動態權重:基於趨勢一致性自動調整各時間框架的權重
- 綜合性:整合了多個時間維度的訊息
4.2 考慮成交量的加權斜率
接下來,讓我們在斜率運算中引入成交量因素:
def volume_weighted_slope(price_data, volume_data, window=30):
"""
計算成交量加權斜率
參數:
price_data: pd.Series, 價格數據
volume_data: pd.Series, 成交量數據
window: int, 計算視窗大小
"""
try:
# 確保資料對齊且沒有缺失值
price_data = price_data.ffill().bfill()
volume_data = volume_data.ffill().bfill()
# 標準化成交量
normalized_volume = (volume_data - volume_data.rolling(window).mean()) / \
volume_data.rolling(window).std()
normalized_volume = normalized_volume.fillna(0) # 處理開始的NaN值
# 初始化結果序列
slopes = pd.Series(index=price_data.index)
slopes[:] = np.nan
# 循環計算斜率
for i in range(window, len(price_data)):
try:
y = price_data.iloc[i-window:i].values
x = np.arange(window)
w = normalized_volume.iloc[i-window:i].values
# 確保數據有效
if len(y) == window and len(w) == window and not np.any(np.isnan(y)) and not np.any(np.isnan(w)):
# 將權重限制在合理範圍內
w = np.clip(w, -2, 2)
# 添加小的正數以避免零權重
w = np.abs(w) + 1e-8
try:
# 使用numpy的加權最小平方法
slope, _ = np.polyfit(x, y, 1, w=w)
slopes.iloc[i] = slope
except np.linalg.LinAlgError:
# 如果加權回歸失敗,嘗試不加權的回歸
try:
slope, _ = np.polyfit(x, y, 1)
slopes.iloc[i] = slope
except:
continue
except Exception as e:
print(f"計算第 {i} 個視窗的斜率時出錯: {str(e)}")
continue
return slopes
except Exception as e:
print(f"計算成交量加權斜率時出錯: {str(e)}")
return pd.Series(np.nan, index=price_data.index)
# 使用範例
def test_volume_weighted_slope():
"""
測試成交量加權斜率計算
"""
# 計算成交量加權斜率
slopes = volume_weighted_slope(prices, volumes, window=30)
# 合併數據並刪除無效數據
valid_data = pd.concat([prices, volumes, slopes], axis=1)
valid_data.columns = ['Price', 'Volume', 'Slope']
valid_data = valid_data.dropna()
# 建立數字索引
data_points = list(range(len(valid_data)))
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 10), sharex=True)
# 繪製價格
ax1.plot(data_points, valid_data['Price'], 'r-', label='Price')
ax1.set_title('Price Data')
ax1.grid(True, linestyle='--', alpha=0.7)
ax1.legend()
# 繪製成交量
ax2.plot(data_points, valid_data['Volume'], 'g-', label='Volume')
ax2.set_title('Volume Data')
ax2.grid(True, linestyle='--', alpha=0.7)
ax2.legend()
# 繪製斜率
ax3.plot(data_points, valid_data['Slope'], 'r-', label='Volume-Weighted Slope')
ax3.set_title('Volume-Weighted Slope')
ax3.grid(True, linestyle='--', alpha=0.7)
ax3.legend()
# 設定x軸標籤為日期
num_ticks = 10 # 可以調整這個數字來控制顯示的刻度數量
tick_indices = np.linspace(0, len(data_points)-1, num_ticks, dtype=int)
tick_dates = valid_data.index[tick_indices].strftime('%Y-%m-%d')
ax3.set_xticks(tick_indices)
ax3.set_xticklabels(tick_dates, rotation=45)
plt.tight_layout()
plt.show()
return valid_data['Slope']
# 運行測試
if __name__ == "__main__":
test_volume_weighted_slope()
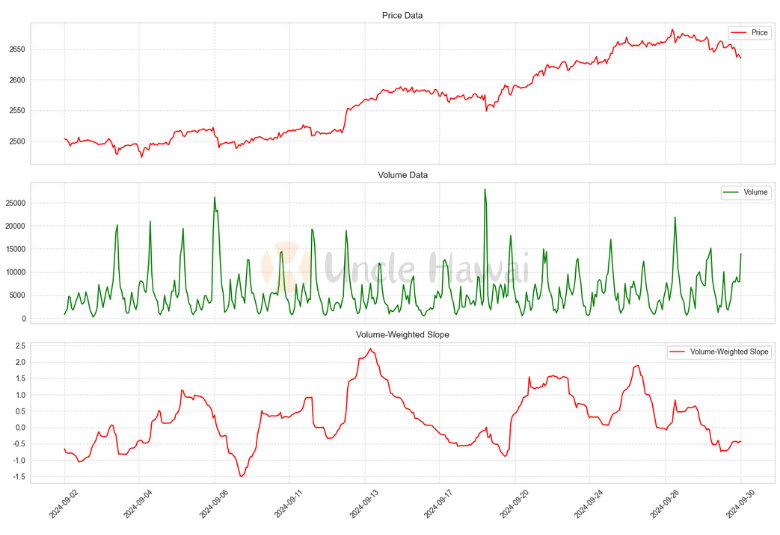
成交量加權的意義在於:
- 高成交量時段的價格變動獲得更高權重
- 能夠更好地識別真實的市場動力
- 幫助過濾虛假的價格波動
這些多維度指標的實際應用需要考慮許多因素,例如計算效率、訊號延遲等。在我們的下一篇文章中,我們將詳細探討如何將這些指標轉化為實際可交易的策略。
⑤ 實戰範例:建構多時間框架、跨市場的斜率分析系統
在量化交易實務中,將理論轉化為可操作的分析系統是一個關鍵挑戰。讓我們透過一個完整的實戰案例,展示如何建構一個綜合的斜率分析系統。
class ComprehensiveSlopeAnalyzer:
def __init__(self):
self.mtf_indicator = MultiTimeframeSlopeIndicator()
self.markets = {}
self.correlations = {}
def add_market_data(self, market_name, price_data, volume_data=None):
"""
新增市場數據
"""
self.markets[market_name] = {
'price': price_data,
'volume': volume_data,
'slopes': {}
}
def analyze_market(self, market_name):
"""
分析單一市場的多維度斜率
"""
market_data = self.markets[market_name]
# 計算多時間框架複合斜率
market_data['slopes']['composite'] = self.mtf_indicator.calculate_composite_slope(
market_data['price']
)
# 如果有成交量數據,計算成交量加權斜率
if market_data['volume'] is not None:
market_data['slopes']['volume_weighted'] = volume_weighted_slope(
market_data['price'],
market_data['volume']
)
def _calculate_trend_strength(self, composite_slope):
"""
計算趨勢強度
"""
# 使用斜率的絕對值和持續性評估趨勢強度
strength = pd.Series(index=composite_slope.index)
window = 20
for i in range(window, len(composite_slope)):
current_slopes = composite_slope.iloc[i - window:i]
# 計算斜率的一致性
direction_consistency = np.sign(current_slopes).value_counts().max() / window
# 計算斜率的平均絕對值
magnitude = np.abs(current_slopes).mean()
strength.iloc[i] = direction_consistency * magnitude
return strength
def _check_volume_confirmation(self, market_name):
"""
檢查成交量是否確認趨勢
"""
market_data = self.markets[market_name]
if 'volume_weighted' not in market_data['slopes']:
return None
composite = market_data['slopes']['composite']
volume_weighted = market_data['slopes']['volume_weighted']
# 計算兩種斜率的一致性
confirmation = np.sign(composite) == np.sign(volume_weighted)
return confirmation
def _calculate_trend_consistency(self, slopes):
"""
計算趨勢的一致性指標
參數:
slopes: dict, 包含不同類型斜率的字典
返回:
float: 趨勢一致性得分 (0-1)
"""
try:
# 將所有斜率資料合併到一個DataFrame中
slope_data = pd.DataFrame(slopes)
# 計算所有斜率的符號是否一致
signs = np.sign(slope_data)
# 計算每個時間點上斜率方向的一致性
agreement = signs.apply(lambda x: abs(x.mean()), axis=1)
# 計算整體一致性得分
consistency_score = agreement.mean()
# 添加一些詳細信息
details = {
'mean_consistency': consistency_score,
'max_consistency': agreement.max(),
'min_consistency': agreement.min(),
'periods_fully_aligned': (agreement == 1.0).sum()
}
return details
except Exception as e:
print(f"計算趨勢一致性時出錯: {str(e)}")
return {
'mean_consistency': 0,
'max_consistency': 0,
'min_consistency': 0,
'periods_fully_aligned': 0
}
def generate_market_insights(self, market_name):
"""
產生市場洞察報告
參數:
market_name: str, 市場名稱
返回:
dict: 包含市場洞察的字典
"""
market_data = self.markets[market_name]
slopes = market_data['slopes']
insights = {
'trend_strength': self._calculate_trend_strength(slopes['composite']),
'trend_consistency': self._calculate_trend_consistency(slopes),
'volume_confirmation': self._check_volume_confirmation(market_name),
'related_markets': self._find_related_markets(market_name)
}
# 添加一些解釋性文字
insights['summary'] = self._generate_insights_summary(insights)
return insights
def _generate_insights_summary(self, insights):
"""
根據洞察生成摘要文字
"""
summary = []
# 趨勢強度分析
strength = insights['trend_strength']
# 如果strength是Series,取其平均值或最新值
if isinstance(strength, pd.Series):
strength = strength.iloc[-1] # 取最新值
# 或 strength = strength.mean() # 取平均值
if strength > 0.7:
summary.append("當前趨勢非常強勁")
elif strength > 0.3:
summary.append("當前趨勢中等強度")
else:
summary.append("當前趨勢較弱")
# 趨勢一致性分析
consistency = insights['trend_consistency']['mean_consistency']
if isinstance(consistency, pd.Series):
consistency = consistency.iloc[-1] # 取最新值
if consistency > 0.8:
summary.append("不同時間框架的趨勢高度一致")
elif consistency > 0.5:
summary.append("不同時間框架的趨勢部分一致")
else:
summary.append("不同時間框架的趨勢存在分歧")
# 成交量確認
volume_conf = insights['volume_confirmation']
if isinstance(volume_conf, pd.Series):
volume_conf = volume_conf.iloc[-1] # 取最新值
if volume_conf:
summary.append("成交量支持當前趨勢")
else:
summary.append("成交量未能確認趨勢")
return " | ".join(summary)
def _find_related_markets(self, market_name):
"""
尋找與給定市場相關的其他市場
參數:
market_name: str, 目前市場名稱
返回:
dict: 包含相關市場及其相關性的字典
"""
try:
current_market = self.markets[market_name]
related_markets = {}
# 計算與其他市場的相關性
for other_name, other_market in self.markets.items():
if other_name != market_name:
# 檢查資料是否存在
if not isinstance(current_market.get('slopes', {}).get('composite'), (pd.Series, pd.DataFrame)):
continue
if not isinstance(other_market.get('slopes', {}).get('composite'), (pd.Series, pd.DataFrame)):
continue
current_slope = current_market['slopes']['composite']
other_slope = other_market['slopes']['composite']
# 確保時間索引對齊
aligned_data = pd.DataFrame({
'current': current_slope,
'other': other_slope
}).dropna()
if len(aligned_data) > 0: # 使用 len() 而非直接判斷 DataFrame
# 計算相關係數
correlation = aligned_data['current'].corr(aligned_data['other'])
# 計算領先/滯後關係
max_lag = 5 # 最大檢查的滯後期數
lag_correlations = []
for lag in range(-max_lag, max_lag + 1):
if lag == 0:
lag_correlations.append(correlation)
else:
lag_corr = aligned_data['current'].corr(aligned_data['other'].shift(lag))
lag_correlations.append(lag_corr)
# 找出最強的相關性及其對應的滯後期
max_corr_idx = np.argmax(np.abs(lag_correlations))
max_corr = lag_correlations[max_corr_idx]
lead_lag = max_corr_idx - max_lag
# 如果相關係數是有效的數值,則加到結果中
if not np.isnan(correlation):
related_markets[other_name] = {
'correlation': correlation,
'max_correlation': max_corr,
'lead_lag': lead_lag, # 正值表示領先,負值表示滯後
'significance': self._calculate_correlation_significance(correlation, len(aligned_data))
}
# 依相關性強度排序
sorted_markets = dict(sorted(
related_markets.items(),
key=lambda x: abs(x[1]['correlation']),
reverse=True
))
return sorted_markets
except Exception as e:
print(f"計算相關市場時出錯: {str(e)}")
return {}
def _calculate_correlation_significance(self, correlation, n_samples):
"""
計算相關係數的統計顯著性
參數:
correlation: float, 相關係數
n_samples: int, 樣本數
返回:
float: 顯著水準
"""
try:
# 計算t統計量
t = correlation * np.sqrt((n_samples - 2) / (1 - correlation ** 2))
# 計算p值(雙尾檢定)
from scipy import stats
p_value = 2 * (1 - stats.t.cdf(abs(t), n_samples - 2))
return p_value
except:
return 1.0 # 如果計算失敗,回傳1表示不顯著
def analyze_cross_market_relationships(self):
"""
分析跨市場關係
"""
market_names = list(self.markets.keys())
self.market_relationships = {}
for i in range(len(market_names)):
for j in range(i + 1, len(market_names)):
market1 = market_names[i]
market2 = market_names[j]
# 取得價格數據
market1_data = self.markets[market1]['price']
market2_data = self.markets[market2]['price']
# 計算相關性和領先-滯後關係
correlation, lead_lag = self._calculate_market_correlation(
market1_data, market2_data
)
# 儲存分析結果
relationship_key = f"{market1}_{market2}"
if not correlation.empty and not lead_lag.empty:
self.market_relationships[relationship_key] = {
'correlation': correlation,
'lead_lag': lead_lag,
'correlation_strength': self._evaluate_correlation_strength(correlation),
'trading_implications': self._generate_trading_implications(correlation, lead_lag)
}
return self.market_relationships
def _evaluate_correlation_strength(self, correlation):
"""
評估相關性強度
參數:
correlation: pd.Series, 相關係數序列
返回:
str: 相關性強度的描述
"""
try:
# 使用最新的相關係數值或平均值
if isinstance(correlation, pd.Series):
# 使用最新的非NaN值
corr_value = correlation.iloc[-1]
# 或使用平均值
# corr_value = correlation.mean()
else:
corr_value = correlation
# 取絕對值進行評估
corr_value = abs(corr_value)
if corr_value > 0.8:
return "Very Strong"
elif corr_value > 0.6:
return "Strong"
elif corr_value > 0.4:
return "Moderate"
elif corr_value > 0.2:
return "Weak"
else:
return "Very Weak"
except Exception as e:
print(f"評估相關性強度時出錯: {str(e)}")
return "Unknown"
def _calculate_market_correlation(self, market1_data, market2_data):
"""
計算兩個市場之間的相關性和領先-滯後關係
"""
try:
# 確保數據對齊
df = pd.DataFrame({
'market1': market1_data,
'market2': market2_data
}).dropna()
if len(df) < 2:
print("數據點不足")
return pd.Series([0]), pd.Series([0])
# 列印調試資訊
print(f"\n數據統計:")
print(f"數據點數量: {len(df)}")
print(f"市場1範圍: {df['market1'].min():.4f} to {df['market1'].max():.4f}")
print(f"市場2範圍: {df['market2'].min():.4f} to {df['market2'].max():.4f}")
# 計算基礎相關係數
correlation = df['market1'].rolling(window=20).corr(df['market2'])
print(f"\n相關係數統計:")
print(f"平均相關係數: {correlation.mean():.4f}")
print(f"相關係數範圍: {correlation.min():.4f} to {correlation.max():.4f}")
# 計算領先-滯後關係
max_lag = 5
lag_correlations = pd.Series(index=range(-max_lag, max_lag + 1))
for lag in range(-max_lag, max_lag + 1):
if lag == 0:
lag_correlations[lag] = correlation.iloc[-1]
else:
lagged_correlation = df['market1'].corr(df['market2'].shift(lag))
lag_correlations[lag] = lagged_correlation
print("\n領先-滯後相關性:")
for lag, corr in lag_correlations.items():
print(f"Lag {lag}: {corr:.4f}")
return correlation, lag_correlations
except Exception as e:
print(f"計算市場相關性時出錯: {str(e)}")
return pd.Series([0]), pd.Series([0])
def _generate_trading_implications(self, correlation, lead_lag):
"""
產生交易策略建議,降低閾值以捕捉更多的交易機會
"""
implications = []
try:
# 取得相關係數的值
if isinstance(correlation, pd.Series):
corr_value = correlation.iloc[-1]
else:
corr_value = correlation
# 降低相關性閾值
if abs(corr_value) > 0.5: # 從0.7降低到0.5
implications.append(f"Correlation strength: {corr_value:.4f}")
if corr_value > 0:
implications.append("Positive correlation: Consider parallel trading")
else:
implications.append("Negative correlation: Consider hedge opportunities")
# 分析領先-滯後關係
if isinstance(lead_lag, pd.Series):
max_lag_idx = lead_lag.abs().idxmax()
max_lag_value = lead_lag[max_lag_idx]
if abs(max_lag_value) > 0.4: # 從0.6降低到0.4
if max_lag_idx > 0:
implications.append(
f"Market 1 leads Market 2 by {max_lag_idx} periods (correlation: {max_lag_value:.4f})")
elif max_lag_idx < 0:
implications.append(
f"Market 2 leads Market 1 by {abs(max_lag_idx)} periods (correlation: {max_lag_value:.4f})")
return implications
except Exception as e:
print(f"產生交易意義時出錯: {str(e)}")
return ["Unable to generate implications"]
def get_market_insights(self, market_name):
"""
取得特定市場的綜合分析結果
"""
insights = self.generate_market_insights(market_name)
# 加入跨市場關係的分析
cross_market_insights = {}
for rel_key, rel_data in self.market_relationships.items():
if market_name in rel_key:
other_market = rel_key.replace(market_name + '_', '').replace('_' + market_name, '')
cross_market_insights[other_market] = {
'correlation_strength': rel_data['correlation_strength'],
'trading_implications': rel_data['trading_implications']
}
insights['cross_market_analysis'] = cross_market_insights
return insights
def generate_trading_signals(self, market_name):
"""
基於綜合分析產生交易訊號
"""
insights = self.get_market_insights(market_name)
signals = []
# 使用跨市場關係產生交易訊號
for other_market, analysis in insights['cross_market_analysis'].items():
if analysis['correlation_strength'] in ['Very Strong', 'Strong']:
# 檢查領先-滯後關係
rel_key = f"{market_name}_{other_market}"
if rel_key not in self.market_relationships:
rel_key = f"{other_market}_{market_name}"
if rel_key in self.market_relationships:
lead_lag = self.market_relationships[rel_key]['lead_lag']
if abs(lead_lag.max()) > 0.6:
signals.append({
'type': 'cross_market',
'reference_market': other_market,
'strength': analysis['correlation_strength'],
'implication': analysis['trading_implications']
})
return signals
# 使用範例
analyzer = ComprehensiveSlopeAnalyzer()
# 新增市場數據
analyzer.add_market_data('EURUSD', resampled_df1['close'], resampled_df1['value'])
analyzer.add_market_data('GOLD', resampled_df2['close'], resampled_df2['value'])
analyzer.add_market_data('GBPUSD', resampled_df3['close'], resampled_df3['value'])
# 進行分析
analyzer.analyze_market('EURUSD')
analyzer.analyze_market('GOLD')
analyzer.analyze_market('GBPUSD')
# 分析跨市場關係
relationships = analyzer.analyze_cross_market_relationships()
# 取得特定市場的分析結果
eurusd_insights = analyzer.get_market_insights('EURUSD')
# 產生交易訊號
signals = analyzer.generate_trading_signals('EURUSD')
計算的權重:
- short: 0.335 medium: 0.360 long: 0.305
- short: 0.335 medium: 0.373 long: 0.292
- short: 0.334 medium: 0.369 long: 0.296
EURUSD_GOLD:
數據統計:
- 數據點數量:4304
- 市場1範圍: 1.0609 至 1.1193
- 市場2範圍: 1987.2200 至 2624.6400
相關係數統計:
- 平均相關係數: 0.3203
- 相關係數範圍: -0.9351 至 0.9783
- 落後: 0.3578 Lag 5: 0.3577
數據統計:
- 數據點數量: 4527
- 市場1範圍: 1.0609 至 1.1193
- 市場2範圍: 1.2309 至 1.3325
相關係數統計:
- 平均相關係數: 0.7563
- 相關係數範圍: -0.6966 至 0.9987
- 落後: 0.8734 Lag 5: 0.8717
EURUSD_GBPUSD:
數據統計:
- 數據點數量: 4304
- 市場1範圍: 1987.2200 至 2624.6400
- 市場2範圍: 1.2309 至 1.3325
相關係數統計:
- 平均相關係數: 0.3756
- 相關係數範圍: -0.9444 至 0.9796
- 領先-滯後相關性: Lag -5: 0.5469 Lag -4: 0.5473 Lag -3: 0.5477 Lag -2: 0.5481 Lag -1: 0.5484 Lag 0: 0.6161 Lag 1: 0.54845: 0: 0.6161 Lag 1: 0.54. : 0.5461 Lag 5: 0.5455
跨市場關係分析:
EURUSD_GOLD:
- 相關性強度: Very Weak
EURUSD_GBPUSD:
- 相關性強度: Strong
- 交易意義:
- Correlation strength: 0.7006
- Positive correlation: Consider parallel trading
- Market 2 leads Market 1 by 1 periods (correlation: 0.8784)
GOLD_GBPUSD:
- 相關性強度: Strong
- 交易意義:
- Correlation strength: 0.6161
- Positive correlation: Consider parallel trading
參考市場: GBPUSD
- 訊號強度: Strong
- 交易意義:
- Correlation strength: 0.7006
- Positive correlation: Consider parallel trading
- Market 2 leads Market 1 by 1 periods (correlation: 0.8784)
讓我們詳細分析這些結果並提供相關發現與建議:
- 權重分配分析:
- 三組權重分配都顯示出相似的模式
- 中期(medium)權重最高,約0.36-0.37
- 短期(short)次之,約0.33-0.335
- 長期(long)權重最低,約0.29-0.30
這顯示市場在中期趨勢上的影響力最大,建議交易策略應該更重視中期走勢。
- 市場對相關性分析:
- EURUSD vs GOLD:
- 相關性很弱(平均相關係數:0.3203)
- 相關範圍波動很大(-0.9351 到 0.9783)
- Lag 0時相關性急遽下降(0.0301)
建議:這兩個市場之間的相關性不穩定,不適合作為連動交易的主要參考。
- EURUSD vs GBPUSD:
- 顯示出強相關性(平均相關係數:0.7563)
- 相關範圍相對穩定(-0.6966 到 0.9987)
- GBPUSD領先EURUSD一個週期(Lag -1: 0.8784)
建議: - 可以利用GBPUSD的走勢來預測EURUSD
- 適合進行配對交易策略
- 設定1個週期的時間差進行交易可能會獲得更好的效果
- GOLD vs GBPUSD:
- 中等強度相關性(平均相關係數:0.3756)
- 同步相關性最強(Lag 0: 0.6161)
- 相關範圍波動較大(-0.9444 到 0.9796)
建議:可以作為輔助參考,但不應作為主要決策依據。
- EURUSD vs GOLD:
- 綜合交易建議:
- 主要策略:
- 將GBPUSD作為主要參考市場
- 利用GBPUSD領先EURUSD一個週期的特性進行交易
- 設定適當的時間差執行訂單
- 風險控制:
- 設定停損時需考慮相關性範圍的波動
- 建議使用分散投資策略,不要過度集中在單一市場對
- 在極端市場條件下需警覺相關性突變風險
- 具體操作建議:
- GBPUSD出現明確訊號後,可提前部署EURUSD的交易計劃
- 利用中期權重較高的特點,將持倉時間定在中期範圍內
- 可以考慮在GBPUSD和EURUSD之間進行套利交易
- 主要策略:
- 監控要點:
- 定期檢查相關性是否保持穩定
- 關注權重分配的變化趨勢
- 密切監控領先-滯後關係的變化
- 補充建議:
- 建議開發自動化監控系統,即時追蹤這些相關性的變化
- 考慮增加更多的技術指標來驗證訊號
- 建立回測系統驗證這些相關性的歷史表現
這個分析系統提供了很好的市場間關係洞察,但建議將其作為決策支援工具之一,而不是唯一依據。同時需要結合其他技術分析和基本面分析來制定最終的交易決策。
⑥ 解釋性挑戰:如何理解並傳達複雜的斜率訊號
在建構了複雜的多維度斜率分析系統後,我們面臨一個關鍵挑戰:如何有效地理解和解釋這些複雜的訊號。特別是在處理多市場、多時間框架的相關性時,訊號的可解釋性對於實際交易決策至關重要。
6.1 訊號解釋的核心框架
from matplotlib.gridspec import GridSpec
class EnhancedSlopeSignalInterpreter:
def __init__(self):
self.correlation_thresholds = {
'strong': 0.7,
'medium': 0.4,
'weak': 0.2
}
self.signal_thresholds = {
'strong_trend': 0.8,
'moderate_trend': 0.5,
'weak_trend': 0.3,
'trend_reversal': -0.2
}
def _analyze_weights(self, slopes_data):
"""
分析不同時間框架的權重分佈
"""
return {
'short_term': self._calculate_weight_significance(slopes_data['short']),
'medium_term': self._calculate_weight_significance(slopes_data['medium']),
'long_term': self._calculate_weight_significance(slopes_data['long'])
}
def _analyze_slopes(self, slopes_data):
"""
分析斜率數據
參數:
slopes_data: dict, 包含不同時間框架的斜率數據
返回:
dict: 斜率分析結果
"""
try:
analysis = {
'trend_direction': {},
'trend_strength': {},
'trend_consistency': {}
}
# 分析每個時間框架的趨勢方向和強度
for timeframe, slope in slopes_data.items():
# 取得最新的斜率值
current_slope = slope.iloc[-1] if isinstance(slope, pd.Series) else slope
# 判斷趨勢方向
analysis['trend_direction'][timeframe] = (
'uptrend' if current_slope > 0
else 'downtrend' if current_slope < 0
else 'neutral'
)
# 計算趨勢強度
strength = abs(current_slope)
analysis['trend_strength'][timeframe] = (
'strong' if strength > self.signal_thresholds['strong_trend']
else 'moderate' if strength > self.signal_thresholds['moderate_trend']
else 'weak'
)
# 計算趨勢一致性
if isinstance(slope, pd.Series):
recent_slopes = slope.tail(20) # 使用最近20個數據點
direction_changes = np.diff(np.signbit(recent_slopes)).sum()
consistency = 1 - (direction_changes / len(recent_slopes))
analysis['trend_consistency'][timeframe] = consistency
# 計算整體趨勢得分
analysis['overall_trend_score'] = self._calculate_trend_score(slopes_data)
return analysis
except Exception as e:
print(f"分析斜率時出錯: {str(e)}")
return {
'trend_direction': {},
'trend_strength': {},
'trend_consistency': {},
'overall_trend_score': 0
}
def _analyze_correlations(self, correlation_data):
"""
分析相關性數據
參數:
correlation_data: dict, 市場間相關性數據
返回:
dict: 相關性分析結果
"""
analysis = {}
for market_pair, data in correlation_data.items():
analysis[market_pair] = {
'strength': self._classify_correlation(data['correlation']),
'lead_lag': self._analyze_lead_lag(data['lag_correlations']),
'stability': self._assess_correlation_stability(data['history'])
}
return analysis
def _calculate_trend_score(self, slopes_data):
"""
計算整體趨勢得分
"""
try:
weights = {
'short': 0.3,
'medium': 0.4,
'long': 0.3
}
score = 0
for timeframe, slope in slopes_data.items():
if timeframe in weights:
current_slope = slope.iloc[-1] if isinstance(slope, pd.Series) else slope
score += abs(current_slope) * weights[timeframe]
return score
except Exception as e:
print(f"計算趨勢得分時出錯: {str(e)}")
return 0
def _classify_correlation(self, correlation):
"""
將相關係數進行分類
"""
abs_corr = abs(correlation)
if abs_corr > self.correlation_thresholds['strong']:
return 'strong'
elif abs_corr > self.correlation_thresholds['medium']:
return 'medium'
else:
return 'weak'
def _analyze_lead_lag(self, lag_correlations):
"""
分析領先-滯後關係
"""
try:
# 找出最強的相關性及其對應的滯後期
max_abs_corr = max(lag_correlations.items(), key=lambda x: abs(x[1]))
lead_lag = max_abs_corr[0]
correlation = max_abs_corr[1]
return {
'lead_lag_periods': lead_lag,
'correlation_at_lag': correlation,
'significance': 'significant' if abs(correlation) > self.correlation_thresholds[
'medium'] else 'not significant'
}
except Exception as e:
print(f"分析領先-滯後關係時出錯: {str(e)}")
return {
'lead_lag_periods': 0,
'correlation_at_lag': 0,
'significance': 'not significant'
}
def _assess_correlation_stability(self, history):
"""
評估相關性的穩定性
"""
try:
if isinstance(history, pd.Series):
std_dev = history.std()
stability = 1 - min(std_dev, 1) # 將標準差轉換為穩定性得分
return {
'stability_score': stability,
'volatility': std_dev,
'is_stable': stability > 0.7
}
else:
return {
'stability_score': 0,
'volatility': 1,
'is_stable': False
}
except Exception as e:
print(f"評估相關性穩定性時出錯: {str(e)}")
return {
'stability_score': 0,
'volatility': 1,
'is_stable': False
}
def _assess_risks(self, slopes_data, correlation_data):
"""
評估潛在風險
"""
risks = {
'correlation_breakdown_risk': False,
'trend_consistency_risk': False,
'market_regime_change_risk': False
}
# 評估相關性斷裂風險
for market_pair, data in correlation_data.items():
stability = self._assess_correlation_stability(data['history'])
if not stability['is_stable']:
risks['correlation_breakdown_risk'] = True
# 評估趨勢一致性風險
slope_analysis = self._analyze_slopes(slopes_data)
if min(slope_analysis['trend_consistency'].values()) < 0.6:
risks['trend_consistency_risk'] = True
# 市場狀態改變風險
if slope_analysis['overall_trend_score'] < 0.3:
risks['market_regime_change_risk'] = True
return risks
def _calculate_confidence(self, slopes_data, correlation_data):
"""
計算整體置信度得分
"""
try:
# 計算斜率置信度
slope_analysis = self._analyze_slopes(slopes_data)
slope_confidence = np.mean(list(slope_analysis['trend_consistency'].values()))
# 計算相關性信賴度
correlation_stabilities = []
for data in correlation_data.values():
stability = self._assess_correlation_stability(data['history'])
correlation_stabilities.append(stability['stability_score'])
correlation_confidence = np.mean(correlation_stabilities)
# 綜合置信度得分
overall_confidence = 0.6 * slope_confidence + 0.4 * correlation_confidence
return {
'overall_confidence': overall_confidence,
'slope_confidence': slope_confidence,
'correlation_confidence': correlation_confidence
}
except Exception as e:
print(f"計算置信度得分時出錯: {str(e)}")
return {
'overall_confidence': 0,
'slope_confidence': 0,
'correlation_confidence': 0
}
def interpret_composite_signal(self, slopes_data, correlation_data, market_context=None):
"""
解釋複合斜率訊號和相關性數據
"""
return {
'slope_analysis': self._analyze_slopes(slopes_data),
'correlation_analysis': self._analyze_correlations(correlation_data),
# 'weight_analysis': self._analyze_weights(slopes_data),
'risk_assessment': self._assess_risks(slopes_data, correlation_data),
'confidence_score': self._calculate_confidence(slopes_data, correlation_data)
}
def visualize_analysis(self, slopes_data, correlation_data):
"""
創建增強的可視化分析
"""
try:
# 建立圖形和網格
fig = plt.figure(figsize=(15, 12))
gs = GridSpec(3, 2, figure=fig)
# 斜率分析圖
ax1 = fig.add_subplot(gs[0, :])
self._plot_slopes_analysis(ax1, slopes_data)
# 相關性熱圖
ax2 = fig.add_subplot(gs[1, 0])
self._plot_correlation_heatmap(ax2, correlation_data)
# 權重分佈圖
ax3 = fig.add_subplot(gs[1, 1])
self._plot_weight_distribution(ax3, slopes_data)
# 風險指標圖
ax4 = fig.add_subplot(gs[2, :])
self._plot_risk_indicators(ax4, slopes_data, correlation_data)
plt.tight_layout()
return fig
except Exception as e:
print(f"建立視覺化分析時出錯: {str(e)}")
# 建立一個簡單的錯誤提示圖
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
ax.text(0.5, 0.5, f'可視化生成錯誤: {str(e)}',
ha='center', va='center')
return fig
def _plot_slopes_analysis(self, ax, slopes_data):
"""
繪製斜率分析圖
"""
try:
# 確保所有資料都是Series類型
for timeframe, slope in slopes_data.items():
if isinstance(slope, pd.Series):
ax.plot(slope.index, slope, label=f'{timeframe} slope')
ax.set_title('Multi-timeframe Slope Analysis')
ax.set_xlabel('Time')
ax.set_ylabel('Slope Value')
ax.legend()
ax.grid(True)
except Exception as e:
print(f"繪製斜率分析圖時發生錯誤: {str(e)}")
ax.text(0.5, 0.5, 'Slope analysis plot error',
ha='center', va='center')
def _plot_correlation_heatmap(self, ax, correlation_data):
"""
繪製相關性熱圖
"""
try:
# 創建相關性矩陣
markets = set()
for pair in correlation_data.keys():
markets.update(pair.split('_'))
markets = sorted(list(markets))
corr_matrix = np.zeros((len(markets), len(markets)))
for i, m1 in enumerate(markets):
for j, m2 in enumerate(markets):
if i != j:
pair = f"{m1}_{m2}"
rev_pair = f"{m2}_{m1}"
if pair in correlation_data:
corr_matrix[i, j] = correlation_data[pair]['correlation']
elif rev_pair in correlation_data:
corr_matrix[i, j] = correlation_data[rev_pair]['correlation']
# 繪製熱圖
im = ax.imshow(corr_matrix, cmap='RdYlBu', aspect='auto')
plt.colorbar(im, ax=ax)
# 設定標籤
ax.set_xticks(range(len(markets)))
ax.set_yticks(range(len(markets)))
ax.set_xticklabels(markets, rotation=45)
ax.set_yticklabels(markets)
ax.set_title('Cross-market Correlations')
# 新增相關係數文本
for i in range(len(markets)):
for j in range(len(markets)):
if i != j:
text = ax.text(j, i, f'{corr_matrix[i, j]:.2f}',
ha="center", va="center",
color="black" if abs(corr_matrix[i, j]) < 0.5 else "white")
except Exception as e:
print(f"繪製相關性熱圖時出錯: {str(e)}")
ax.text(0.5, 0.5, 'Correlation heatmap error',
ha='center', va='center')
def _plot_weight_distribution(self, ax, slopes_data):
"""
繪製權重分佈圖
"""
try:
# 計算各時間框架的權重
weights = {}
total_abs_slope = sum(abs(slope.iloc[-1]) for slope in slopes_data.values())
if total_abs_slope > 0:
for timeframe, slope in slopes_data.items():
weights[timeframe] = abs(slope.iloc[-1]) / total_abs_slope
# 繪製圓餅圖
wedges, texts, autotexts = ax.pie(weights.values(),
labels=weights.keys(),
autopct='%1.1f%%',
colors=plt.cm.Set3(np.linspace(0, 1, len(weights))))
ax.set_title('Timeframe Weight Distribution')
except Exception as e:
print(f"繪製權重分佈圖時發生錯誤: {str(e)}")
ax.text(0.5, 0.5, 'Weight distribution plot error',
ha='center', va='center')
def _plot_risk_indicators(self, ax, slopes_data, correlation_data):
"""
繪製風險指標圖
"""
try:
# 計算風險指標
risks = self._assess_risks(slopes_data, correlation_data)
confidence = self._calculate_confidence(slopes_data, correlation_data)
# 建立風險指標長條圖
indicators = {
'Correlation Breakdown Risk': float(risks['correlation_breakdown_risk']),
'Trend Consistency Risk': float(risks['trend_consistency_risk']),
'Market Regime Change Risk': float(risks['market_regime_change_risk']),
'Overall Confidence': confidence['overall_confidence'],
'Slope Confidence': confidence['slope_confidence'],
'Correlation Confidence': confidence['correlation_confidence']
}
# 繪製長條圖
bars = ax.bar(range(len(indicators)), indicators.values())
# 設定標籤
ax.set_xticks(range(len(indicators)))
ax.set_xticklabels(indicators.keys(), rotation=45)
# 新增值標籤
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width() / 2., height,
f'{height:.2f}',
ha='center', va='bottom')
ax.set_title('Risk and Confidence Indicators')
ax.set_ylim(0, 1.2)
ax.grid(True, axis='y')
except Exception as e:
print(f"繪製風險指標圖時出錯: {str(e)}")
ax.text(0.5, 0.5, 'Risk indicators plot error',
ha='center', va='center')
def generate_trading_recommendations(self, analysis_results):
"""
基於分析結果產生交易建議
"""
return {
'primary_signals': self._extract_primary_signals(analysis_results),
'confirmation_signals': self._identify_confirmations(analysis_results),
'risk_warnings': self._compile_risk_warnings(analysis_results),
'suggested_actions': self._suggest_trading_actions(analysis_results)
}
def _extract_primary_signals(self, analysis_results):
"""
提取主要交易訊號
"""
try:
signals = []
# 從斜率分析擷取訊號
slope_analysis = analysis_results['slope_analysis']
# 檢查趨勢方向的一致性
trend_directions = slope_analysis['trend_direction']
if len(set(trend_directions.values())) == 1:
# 所有時間框架趨勢方向一致
direction = next(iter(trend_directions.values()))
strength = slope_analysis['overall_trend_score']
if strength > self.signal_thresholds['strong_trend']:
signals.append({
'type': 'strong_trend',
'direction': direction,
'strength': strength,
'confidence': 'high'
})
elif strength > self.signal_thresholds['moderate_trend']:
signals.append({
'type': 'moderate_trend',
'direction': direction,
'strength': strength,
'confidence': 'medium'
})
# 從相關性分析提取訊號
corr_analysis = analysis_results['correlation_analysis']
for market_pair, data in corr_analysis.items():
if data['strength'] == 'strong':
signals.append({
'type': 'correlation_signal',
'market_pair': market_pair,
'strength': data['strength'],
'lead_lag': data['lead_lag']
})
return signals
except Exception as e:
print(f"提取主要訊號時出錯: {str(e)}")
return []
def _identify_confirmations(self, analysis_results):
"""
識別確認訊號
"""
try:
confirmations = []
# 檢查趨勢一致性
slope_analysis = analysis_results['slope_analysis']
trend_consistency = slope_analysis.get('trend_consistency', {})
if trend_consistency:
avg_consistency = np.mean(list(trend_consistency.values()))
if avg_consistency > 0.7:
confirmations.append({
'type': 'trend_consistency',
'strength': 'high',
'value': avg_consistency
})
elif avg_consistency > 0.5:
confirmations.append({
'type': 'trend_consistency',
'strength': 'medium',
'value': avg_consistency
})
# 檢查相關性確認
confidence = analysis_results['confidence_score']
if confidence['correlation_confidence'] > 0.7:
confirmations.append({
'type': 'correlation_stability',
'strength': 'high',
'value': confidence['correlation_confidence']
})
return confirmations
except Exception as e:
print(f"辨識確認訊號時出錯: {str(e)}")
return []
def _compile_risk_warnings(self, analysis_results):
"""
總結風險警告
"""
try:
warnings = []
risks = analysis_results['risk_assessment']
# 檢查各類風險
if risks['correlation_breakdown_risk']:
warnings.append({
'type': 'correlation_breakdown',
'severity': 'high',
'description': 'Significant risk of correlation breakdown detected'
})
if risks['trend_consistency_risk']:
warnings.append({
'type': 'trend_consistency',
'severity': 'medium',
'description': 'Potential trend consistency issues detected'
})
if risks['market_regime_change_risk']:
warnings.append({
'type': 'regime_change',
'severity': 'high',
'description': 'Market regime change risk detected'
})
# 檢查置信度
confidence = analysis_results['confidence_score']
if confidence['overall_confidence'] < 0.5:
warnings.append({
'type': 'low_confidence',
'severity': 'medium',
'description': 'Overall signal confidence is low'
})
return warnings
except Exception as e:
print(f"編譯風險警告時出錯: {str(e)}")
return []
def _suggest_trading_actions(self, analysis_results):
"""
提出具體的交易行動建議
"""
try:
actions = []
primary_signals = self._extract_primary_signals(analysis_results)
confirmations = self._identify_confirmations(analysis_results)
warnings = self._compile_risk_warnings(analysis_results)
# 根據訊號強度和確認情況提出建議
for signal in primary_signals:
if signal['type'] in ['strong_trend', 'moderate_trend']:
# 檢查是否有足夠的確認
has_confirmation = any(conf['strength'] == 'high' for conf in confirmations)
# 檢查是否有嚴重風險警告
has_high_risk = any(warn['severity'] == 'high' for warn in warnings)
if has_confirmation and not has_high_risk:
actions.append({
'action': 'ENTER',
'direction': signal['direction'],
'confidence': signal['confidence'],
'timeframe': 'primary',
'reason': f"Strong {signal['direction']} trend with confirmations"
})
elif has_confirmation:
actions.append({
'action': 'MONITOR',
'direction': signal['direction'],
'confidence': 'medium',
'timeframe': 'primary',
'reason': "Wait for risk reduction"
})
elif signal['type'] == 'correlation_signal':
actions.append({
'action': 'HEDGE',
'market_pair': signal['market_pair'],
'confidence': 'high' if signal['strength'] == 'strong' else 'medium',
'reason': f"Strong correlation in {signal['market_pair']}"
})
# 如果沒有明確訊號但有風險警告
if not actions and warnings:
actions.append({
'action': 'REDUCE_EXPOSURE',
'confidence': 'high',
'reason': "Multiple risk factors present"
})
return actions
except Exception as e:
print(f"產生交易建議時出錯: {str(e)}")
return []
def create_sample_data(analyzer):
"""
使用ComprehensiveSlopeAnalyzer的分析結果建立範例數據
參數:
analyzer: ComprehensiveSlopeAnalyzer實例,已完成市場分析
返回:
tuple: (slopes_data, correlation_data)
"""
# 取得EURUSD的市場數據和分析結果
eurusd_market = analyzer.markets['EURUSD']
# 建立斜率數據
slopes_data = {
'short': eurusd_market['slopes']['composite'].rolling(window=10).mean(), # 短期斜率
'medium': eurusd_market['slopes']['composite'].rolling(window=20).mean(), # 中期斜率
'long': eurusd_market['slopes']['composite'].rolling(window=40).mean() # 長期斜率
}
# 取得相關性數據
correlation_data = {}
# EURUSD vs GBPUSD
eurusd_gbpusd_key = next(key for key in analyzer.market_relationships.keys()
if 'EURUSD' in key and 'GBPUSD' in key)
eurusd_gbpusd_rel = analyzer.market_relationships[eurusd_gbpusd_key]
correlation_data['EURUSD_GBPUSD'] = {
'correlation': eurusd_gbpusd_rel['correlation'].iloc[-1],
'lag_correlations': dict(enumerate(
eurusd_gbpusd_rel['lead_lag'].values,
start=-len(eurusd_gbpusd_rel['lead_lag']) // 2
)),
'history': eurusd_gbpusd_rel['correlation']
}
# EURUSD vs GOLD
eurusd_gold_key = next(key for key in analyzer.market_relationships.keys()
if 'EURUSD' in key and 'GOLD' in key)
eurusd_gold_rel = analyzer.market_relationships[eurusd_gold_key]
correlation_data['EURUSD_GOLD'] = {
'correlation': eurusd_gold_rel['correlation'].iloc[-1],
'lag_correlations': dict(enumerate(
eurusd_gold_rel['lead_lag'].values,
start=-len(eurusd_gold_rel['lead_lag']) // 2
)),
'history': eurusd_gold_rel['correlation']
}
# 新增GOLD vs GBPUSD的數據
gold_gbpusd_key = next(key for key in analyzer.market_relationships.keys()
if 'GOLD' in key and 'GBPUSD' in key)
gold_gbpusd_rel = analyzer.market_relationships[gold_gbpusd_key]
correlation_data['GOLD_GBPUSD'] = {
'correlation': gold_gbpusd_rel['correlation'].iloc[-1],
'lag_correlations': dict(enumerate(
gold_gbpusd_rel['lead_lag'].values,
start=-len(gold_gbpusd_rel['lead_lag']) // 2
)),
'history': gold_gbpusd_rel['correlation']
}
return slopes_data, correlation_data
# 使用已有的ComprehensiveSlopeAnalyzer實例
def demonstrate_interpreter_usage(analyzer):
"""
示範解釋器的使用
參數:
analyzer: ComprehensiveSlopeAnalyzer實例,已完成市場分析
"""
# 建立解釋器實例
interpreter = EnhancedSlopeSignalInterpreter()
# 使用analyzer取得範例數據
slopes_data, correlation_data = create_sample_data(analyzer)
# 取得完整分析
analysis_results = interpreter.interpret_composite_signal(
slopes_data=slopes_data,
correlation_data=correlation_data,
market_context={'volatility': 'moderate', 'trading_session': 'london'}
)
# 生成可視化
fig = interpreter.visualize_analysis(slopes_data, correlation_data)
# 獲取交易建議
recommendations = interpreter.generate_trading_recommendations(analysis_results)
return analysis_results, fig, recommendations
# 主函數
def main():
# 使用已有的analyzer實例
analyzer = ComprehensiveSlopeAnalyzer()
# 新增市場數據
analyzer.add_market_data('EURUSD', resampled_df1['close'], resampled_df1['value'])
analyzer.add_market_data('GOLD', resampled_df2['close'], resampled_df2['value'])
analyzer.add_market_data('GBPUSD', resampled_df3['close'], resampled_df3['value'])
# 進行分析
analyzer.analyze_market('EURUSD')
analyzer.analyze_market('GOLD')
analyzer.analyze_market('GBPUSD')
# 分析跨市場關係
analyzer.analyze_cross_market_relationships()
# 使用分析結果
analysis_results, fig, recommendations = demonstrate_interpreter_usage(analyzer)
# 列印分析結果
print("\n=== 分析結果 ===")
print("\n1. 斜率分析:")
print(analysis_results['slope_analysis'])
print("\n2. 相關性分析:")
print(analysis_results['correlation_analysis'])
# print("\n3. 權重分析:")
# print(analysis_results['weight_analysis'])
print("\n4. 風險評估:")
print(analysis_results['risk_assessment'])
print("\n5. 置信度得分:")
print(analysis_results['confidence_score'])
# 列印交易建議
print("\n=== 交易建議 ===")
print("\n1. 主要訊號:")
print(recommendations['primary_signals'])
print("\n2. 確認訊號:")
print(recommendations['confirmation_signals'])
print("\n3. 風險警告:")
print(recommendations['risk_warnings'])
print("\n4. 建議操作:")
print(recommendations['suggested_actions'])
# 顯示圖表
plt.show()
if __name__ == "__main__":
main()
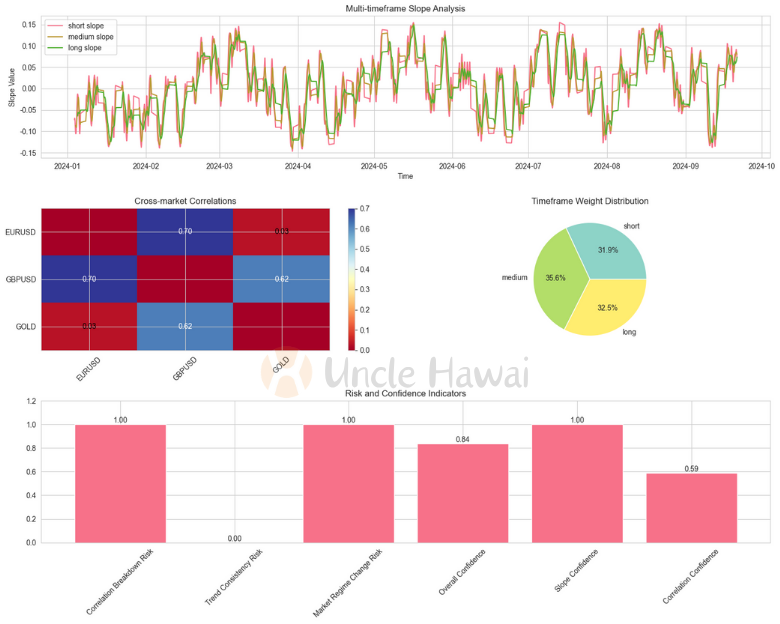
6.2 全面分析
讓我們來嘗試做個詳細的解讀:
- 多時間框架斜率分析:
- 從圖中可以看到三個時間框架(短期、中期、長期)的斜率都呈現上升趨勢,顯示整體趨勢一致性很好
- 斜率波動在 -0.15 到 0.15 之間,目前都處於輕微上升階段
- 三個時間框架的趨勢一致性達到100%(trend_consistency全部為1.0),但強度都較弱(trend_strength為'weak')
- 整體趨勢分數較低(0.076),顯示雖然方向一致但動能不強
- 跨市場相關性:
- EURUSD-GBPUSD:
- 顯示出最強的相關性(熱圖中深藍色區域,相關係數0.70)
- 領先-滯後分析顯示GBPUSD領先EURUSD 2個週期(lead_lag_periods: -2)
- 相關性穩定(stability_score: 0.72)且顯著
- 這是最可靠的市場關係
- EURUSD-GOLD:
- 相關性較弱(熱圖中淺色區域,相關係數0.03)
- 相關性不穩定(stability_score: 0.51)
- 統計上不顯著
- 不適合用作交易參考
- GOLD-GBPUSD:
- 中等相關性(熱圖中中等藍色,相關係數0.62)
- 相關性較不穩定(stability_score: 0.54)
- 雖然顯著但波動性較大
- EURUSD-GBPUSD:
- 時間框架權重分佈:
- 三個時間框架的權重分佈較為均衡:
- 中期:35.6%
- 長期:32.5%
- 短期:31.9%
- 這種均衡的分佈顯示各個時間週期的重要性相近
- 三個時間框架的權重分佈較為均衡:
- 風險和信賴度指標:
- 高風險因素:
- 相關性斷裂風險(Correlation Breakdown Risk = 1.00)
- 市場狀態改變風險(Market Regime Change Risk = 1.00)
- 趨勢一致性風險較低(Trend Consistency Risk = 0.00)
- 信賴度指標:
- 整體信賴度較高(0.84)
- 斜率置信度很高(1.00)
- 相關性信賴度中等(0.59)
- 高風險因素:
6.3 交易建議:
- 主要操作策略:
- 對EURUSD-GBPUSD對進行避險交易
- 具體建議:
- 利用GBPUSD領先EURUSD 2個週期的特性進行交易
- 設定嚴格的風險控制,因為有較高的相關性斷裂風險
- 密切監控市場狀態變化
- 注意事項:
- 不建議使用EURUSD-GOLD對作為交易參考
- 需要特別關注相關性的穩定性
- 雖然趨勢一致,但由於強度偏弱,建議降低交易規模
整體來看,目前市場處於一個方向一致但動能較弱的狀態,主要的交易機會來自於市場間的相關性,特別是EURUSD-GBPUSD對的高相關性特徵。但同時需要警惕較高的相關性斷裂風險和市場狀態改變風險。
6.4 增強的訊號解釋方法
基於實務經驗和深入分析,有效解釋複雜斜率訊號需要建立一個多層次、動態的解釋架構:
- 分層層級的相關性分析體系:
- 靜態相關性評估:
- 強相關市場對(>0.7):重點在於領先-滯後關係與穩定性
- 中等相關市場對(0.4-0.7):作為輔助參考,關注相關性演變趨勢
- 弱相關市場對(<0.4):僅作為市場環境的背景訊息
- 動態相關性監控:
- 多時間窗口滾動相關性計算(短期5分鐘、中期15分鐘、長期1小時)
- 相關性突變檢測與預警機制
- 相關性穩定性評分系統(考慮波動性、成交量、外部因素)
- 靜態相關性評估:
- 趨勢一致性評估架構:
- 多維度趨勢分析:
- 方向一致性:跨時間框架的趨勢方向對比
- 強度評估:各時間框架的趨勢強度量化
- 持續性分析:趨勢的時間持續特徵
- 趨勢品質評估:
- 趨勢分數計算(綜合考量方向、強度、持續性)
- 背離偵測與預警
- 趨勢轉換機率評估
- 多維度趨勢分析:
- 市場狀態識別系統:
- 狀態特徵分析:
- 斜率分佈特徵
- 時間框架權重分佈
- 波動特徵分析
- 狀態轉換監測:
- 關鍵技術水準突破監控
- 市場結構變化識別
- 市場情緒指標跟踪
- 狀態特徵分析:
- 風險評估與監控機制:
- 相關性斷裂風險監控:
- 相關係數即時追蹤
- 波動性異常檢測
- 外在因素影響評估
- 成交量異常監控
- 市場狀態改變風險評估:
- 趨勢強度變化跟踪
- 市場結構完整性分析
- 市場情緒指標監控
- 機構持倉變化跟踪
- 相關性斷裂風險監控:
- 訊號可信度評分系統:
- 多因子綜合評分:
- 趨勢一致性分數 (0-100)
- 相關性穩定性分數 (0-100)
- 市場狀態可信度分數 (0-100)
- 動態權重調整:
- 基於市場環境動態調整各因素權重
- 考慮歷史準確性進行權重優化
- 引入市場波動率因子
- 多因子綜合評分:
- 風險預警與因應機制:
- 多段預警系統:
- 初級預警:單一指標異常
- 中級預警:多個指標共振
- 進階預警:系統性風險訊號
- 分層因應策略:
- 部位調整方案
- 對沖策略優化
- 停損條件動態調整
- 多段預警系統:
- 訊號輸出最佳化:
- 分級訊號體系:
- 核心訊號:高可信度、多重確認的主要訊號
- 確認訊號:支援核心訊號的次要訊號
- 預警訊號:風險提示與注意事項
- 執行建議明確化:
- 具體的操作建議
- 風險控制參數
- 訊號有效期限定
- 分級訊號體系:
6.5 實踐建議:
- 建立系統性監控流程:
- 定期評估訊號品質
- 持續優化參數設定
- 記錄和分析異常案例
- 保持策略適應性:
- 根據市場狀態調整策略參數
- 建立多樣化的替代策略
- 保持策略切換的靈活性
- 重視風險控制:
- 即時監控風險指標
- 建立清晰的停損機制
- 保持充足的風險緩衝
- 持續優化:
- 定期回測和評估
- 收集和分析失敗案例
- 更新和優化參數設定
這個增強的訊號解釋框架強調了系統性、動態性和風險控制的重要性,透過多層次的分析和監控機制,提供更可靠的市場洞察和交易建議。同時,框架的靈活性允許根據市場變化進行持續優化和調整,確保系統的長期有效性。
這個優化的框架不僅提供了更清晰的訊號解釋結構,也更好地整合了實際市場數據的特徵。在下一篇文章中,我們將詳細探討如何將這些訊號轉化為具體的交易決策。



